


Chain of Thought: Lebih Santun dengan LLM
Jangan nge-gas, pikir dulu sebelum ngomong. Ternyata kalau dalam dunia per-LLM-an, ini menjadi pakem yang sering dikenal sebagai CoT atau Chain of Thought.
Berikut lukisan contoh perjalanannya. Dari satu pertanyaan sederhana, panggilan LLM pertama (katalah sebagai tahap Reason) hanya untuk berpikir dan bernalar lebih dalam. Panggilan LLM yang kedua baru (Respond) baru bertugas untuk menawarkan jawaban akhir.
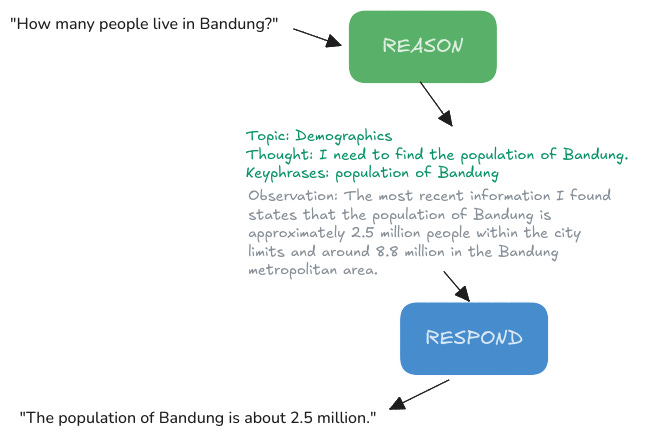
Ini hanyalah salah satu contoh ngoding dengan LLM yang memanfaatkan CoT. Lengkapnya bisa disimak di contoh program yang sudah saya siapkan di github.com/ariya/query-llm.
Sumber inspirasinya tentunya adalah paper tersohor yang menjabarkan gagasan ini, yakni Chain-of-Thought Prompting Elicits Reasoning in Large Language Models yang bisa dibaca di arxiv.org/abs/2201.11903.
Satu lagi penelitian yang sangat menarik tentang hal ini adalah konsep Reason-Act, sering diringkas ReAct (tidak ada hubungannya dengan framework JavaScript untuk membuat front-end). Papernya berjudul ReAct: Synergizing Reasoning and Acting in Language Models, cocok dicerna dari https://arxiv.org/abs/2210.03629.
Untuk penerapan solusi Reason-Act secara gamblang, yang saya sukai adalah contoh dari bang Simon Willison (dulu ikut membuat Django) yang gampang diikusi: til.simonwillison.net/llms/python-react-pattern.
Kalau dilihat, dari diagram di awal, aneh nggak melihat si LLM disuruh kerja dua kali? Toh jawabannya juga akhirnya sama aja. Nah, simpan dulu pandangan ini, satu saat akan berguna begitu ada pembahasan RAG (Retrieval-Augmented Generation).
Di sisi lain, perhatikan juga bagaimana LLM disuruh pura-pura mencari informasi yang dibutuhkan, andainya dia punya akses ke mesin pencari seperti Google. Ini hanya pura-pura aja ya, dalam contoh kode ini, tidak ada akses nyata ke Google.
Untuk menyundul si LLM supaya berpikir seolah-olah akan mengetikkan kata-kata kunci ke Google, promptnya berwujud kurang lebih seperti ini.

Hasil pemikiran si LLM, yang ada topic, thought, keyphrases, dll sering disebut sebagai "inner monologue" dalam berbagai literatur.
Perhatikan lagi bahwa ada contoh yang disisipkan sebagai bagian "system prompt". Ini namanya few-shot prompt, atau juga dikenal sebagai in-context learning (ICL) yang sudah sempat dijabarkan tempo hari, Menyundul LLM dengan Contoh Nyata.
Apakah cara CoT seperti ini masih relevan di jaman DeepSeek R1? Apa hubungan antara CoT dan percakapan bergilir (multi-turn conversation)? Bagaimana peran CoT untuk mensukseskan RAG (retrieval-augmented generation)?
Masih banyak yang bisa kita pelajari bareng-bareng!
Gagasan di balik Chain of Thought ini pernah saya kupas di sebuah utas Threads.