


Ulasan Jujur Lusinan LLMaaS
Ada lusinan penyedia akses LLM lewat API. Saya pernah ngetes hampir semuanya, manual dan otomatis.
AI21, Antropic, Avian, Cerebras, Deep Infra, DeepSeek, Fireworks, Gemini, Glama, Groq, Hyperbolic, Lepton, Mistral, Nebium, Novita, OpenAI, OpenRouter, Together, dan masih banyak lagi.
Kala saya mengujinya secara otomatis, selalu lewat CI, seperti barang bukti stikernya GitHub Actions yang ini.

Mana yang nyaman dipakai dan juga kinerjanya cemerlang? Berikut ringkasan ulasannya.
Perhatikan bahwa walaupun ada bejibun LLMaaS (LLM as a Service), hampir semuanya mengadopsi standar API yang mula-mula digagaskan OpenAI. Ini adalah standar yang sifatnya sudah "de facto". Barusan saya bahas di Mufakat dalam Merangkul LLM.

Dari sekian banyak LLMaaS, rekomendasi saya seperti ini.
Kalau baru pertama kali banget ngoding LLM, pakailah layanan yang ditawarkan oleh lab-lab besar seperti OpenAI, Antrophic, Gemini, dan Mistral. Karena timnya gede dan dananya gemuk, kestabilan sistem sudah bisa dijamin. Memang tidak akan 100% tapi juga nggak gampang mati sekenanya.
Tambahan lagi, biasanya batasan pemakaian (rate limit) sudah lumayan tinggi, sehingga cocok di production.
Bingung yang mana di antara yang empat? Pilih Gemini, karena paling murah (apalagi yang Flash).
Kalau sudah tumbuh kemahiran ngoprek, nah cobalah model-model yang tidak proprietary lagi (seperti Llama, Qwen, DeepSeek, dsb). Sekarang tentunya harus menggunakan LLMaaS yang berbeda.
Saran saya adalah pakai yang sifatnya gateway atau proxy, seperti OpenRouter atau Glama. Kalau harus milih, mending OpenRouter karena lebih populer dan banyak pilihan modelnya.
Untuk perbandingan detil antara inferensi vs model, bisa mencerna utas yang saya tuliskan tempo hari, Kuadran LLM: Inferensi vs Model. Untung ruginya bisa diperhatikan dengan seksama, dan jadi bahan perbandingan yang mendalam.
Bila sudah sreg dengan pilihan model yang nyaman, nah bisa tuh ninggalin OpenRouter/Glama, dan langsung aja ke provider aslinya. Dari pengalaman saya, dua yang bagus adalah Deep Infra atau Avian, karena rate limitnya sangat bersahabat. Jadi kalau produk yang diluncurkan tiba-tiba viral dan digandrungi banyak orang, nggak perlu kena HTTP 429.
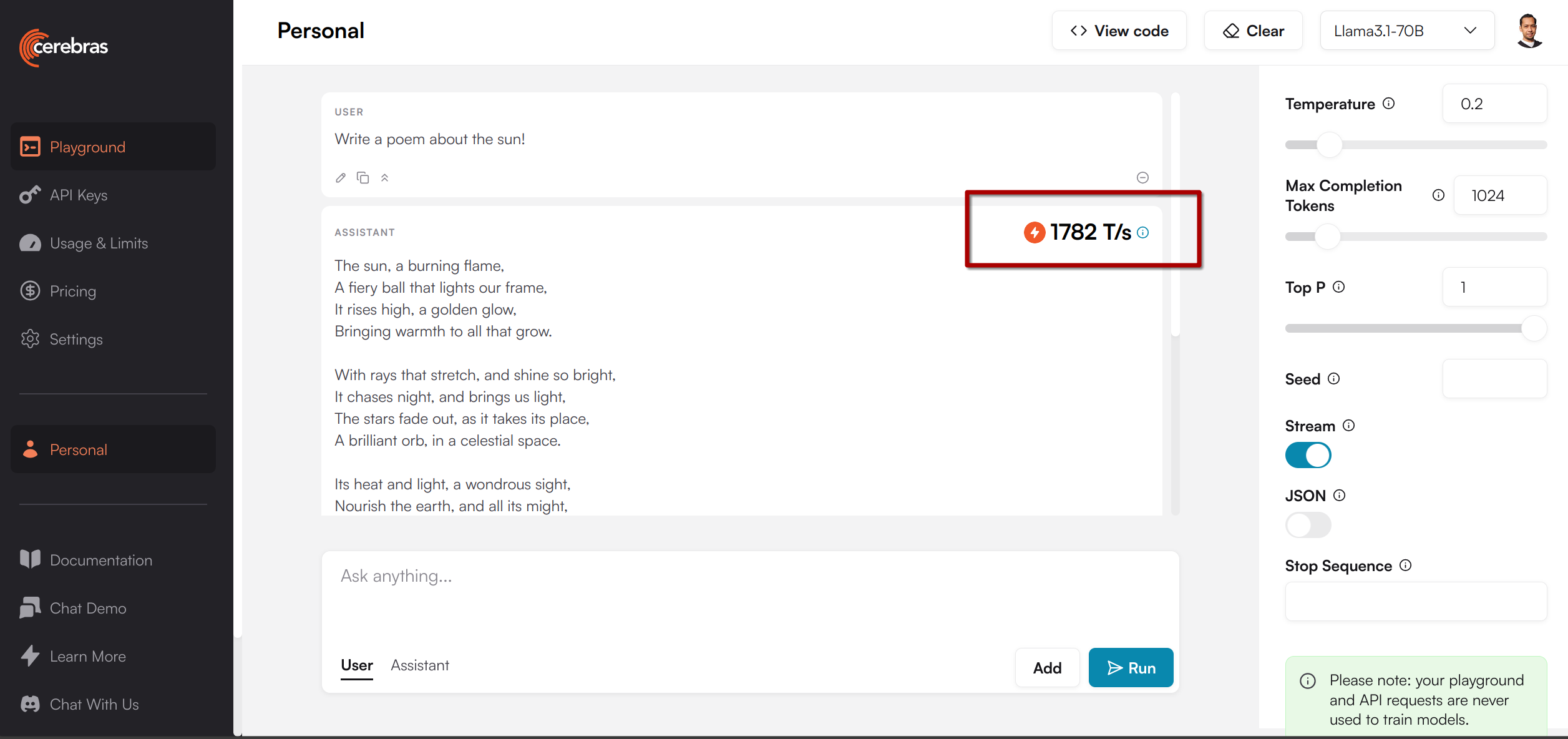
Yang sangat berkesan tapi sayangnya hanya buat demo adalah Groq (bukan Grok), Samba Nova, dan Cerebras. Kecepatan tokennya gila sih, tapi sayang belum siap sama sekali untuk production. Lihat juga 1700 tok/s dengan Cerebras.
Di sini lain, untuk sekedar percobaan dan eksperimen, selalu bisa dimulai dengan menjalankan inferensi LLM lokal dulu. Berikut trik yang pernah saya bagikan: Cortex untuk LLM.
Ayo kita cerdas ber-LLM!
Ulasan ini sebelumnya pernah disebarkan melalui sebuah utas di Threads.